
natural language processing FOR LOW-RESOURCE LANGUAGES
Working within a framework of data sovereignty and cultural protocol, we are applying machine learning methods to make legacy written and recorded documentation more accessible for community-based language reclamation and research.

Principal Investigator
Daisy Rosenblum
Project Team
Partners
Shruti Rijhwani, Graham Neubig, Milind Agarwal, Antonis Anastasopoulous, Dante Cerron, Saughmon Boujkian, Ailar Mahdizadeh, Michaela King, Jaymyn LaVallee, Cate Ngieng
This area of our work focuses on applying computational strategies – machine learning, neural networks, and other types of artificial intelligence – to make written and spoken documentation of Indigenous languages more accessible. In order to do this, we assemble datasets: transcribed recordings of speech, descriptions of photographs, scanned images of text accompanied by transcriptions, and then use those to train machines to make reliable predictions. The data we assemble for a given language is guided by ethical considerations and understanding of diverse community contexts and access protocols
Legacy documentation of Indigenous languages, in recordings, images, and text, is precious to the descendants of those speakers, many of whom are working to revitalize their languages. Many other communities around the world also speak languages which have sparse written or spoken documentation. In comparison to English and other large world languages, these are all ‘low-resource’ languages with small amounts of data available for training models, whether spoken or written. This work makes precious documentation accessible to communities, demonstrates strategies which respect data sovereignty, and pushes the boundaries of state-of-the-art artificial intelligence using sparse data.
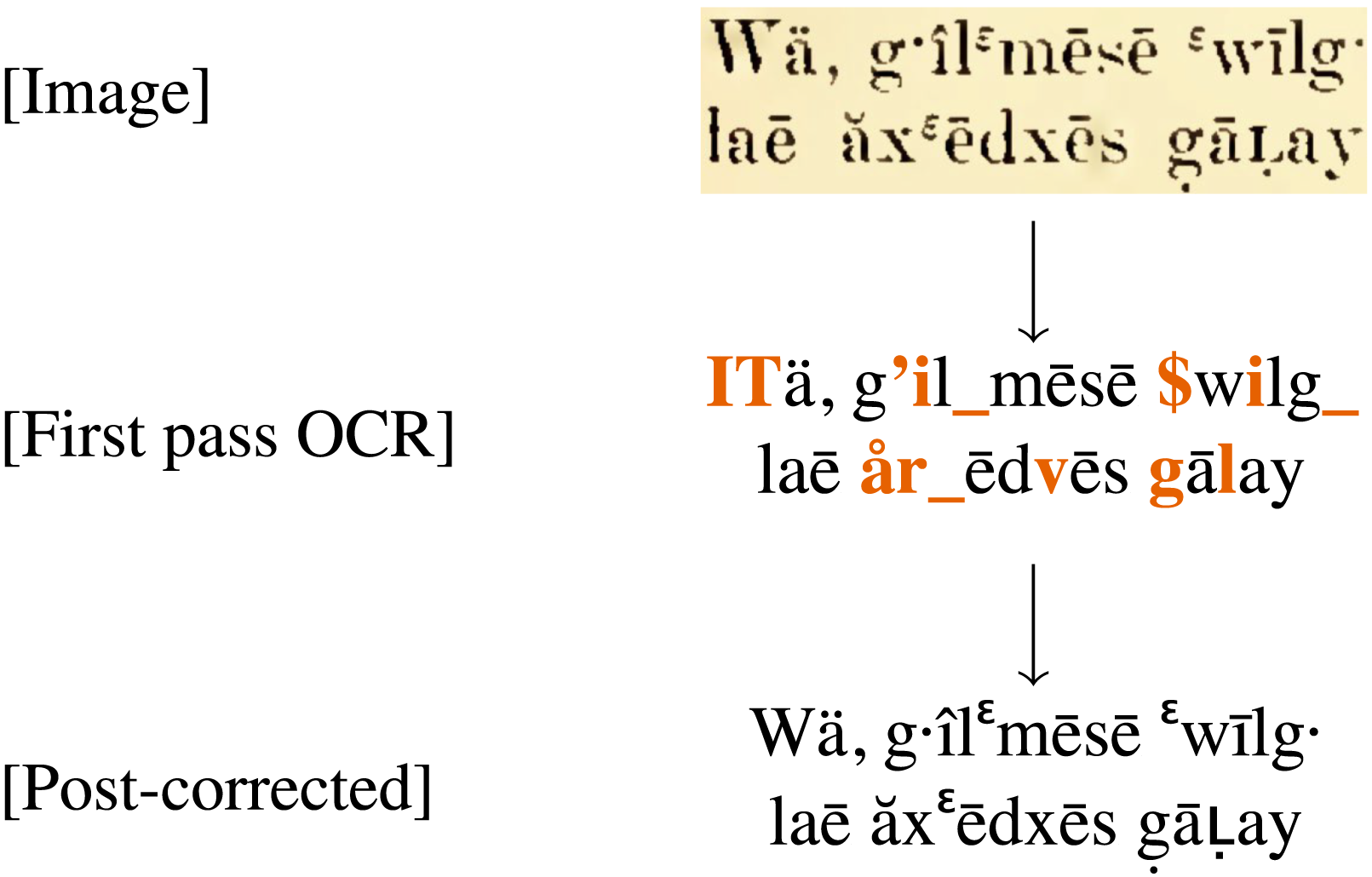
Early OCR model systems struggle to recognize over 30% of the characters used in early Kwak̕wala texts published by George Hunt and Franz Boas. Our improved model lowered the error rate to 4%. (Screen captures: Shruti Rijhwani)

Mikael Willie records memories with Gwa’sala-’Nakwaxda’xw Elder, the late Lily Johnny, in November 2009. (Photo: Daisy Rosenblum)
-
OCR makes PDF images of text machine-readable and searchable; we take accurate OCR for granted in the digital documents we use these days. But reliable OCR does not exist for many languages, especially for older writing systems. Much of the earliest documentation of the Kwak̕wala-Bak̕wa̱mk̓ala language was written over a hundred years ago in a complex system developed by anthropologist Franz Boas and George Hunt, an Indigenous ethnographer and scholar based in Tsax̱is (Fort Rupert). The cultural and linguistic materials written in this system are of tremendous value to community-based researchers, but are minimally accessible in their current form.
Rosenblum, Kwak'wala language learners, and computational linguists at Carnegie Mellon and George Mason University have been working to improve the OCR system for thousands of pages of legacy materials written in the Boas-Hunt orthography. We have produced searchable copies of these significant cultural resources, as well as automating their transliteration into both community-preferred orthographies, vastly increasing their accessibility. You can read more about the project here at Shruti Rijhwani's github page. (Shruti was named to the Forbes 30 Under 30 in Science for this work.) Since then, we have refined the process and made it reliable, and we are extending this process to other valuable texts with more challenging formats, such as dictionaries and interlinear glossing, and to other languages. We are also creating a non-technical user-interface that will facilitate wide-spread access.
-
ASR allows us to dictate text messages or ask Siri to make a phone call. Like OCR, ASR models work well because they have been trained on lots of data—lots of examples of transcribed speech. But Indigenous and other ‘low-resource’ languages have even less access to transcribed recordings of speech than they do to transcribed text.
For many languages, these recordings exist but haven’t been transcribed. For Indigenous language revitalization, recordings of speech are precious resources for language teaching and learning. They become exponentially more useful once they are transcribed and translated, and can be mobilized to create other resources for learners.
The ‘transcription bottleneck’ describes the challenge facing so many community language programs: one minute of recording can take up to an hour to transcribe. Furthermore, knowing how to hear and represent the sounds in the language—that is, to transcribe it—is also a highly specialized skill that takes significant time to develop. However, community language programs and their learners are focused on spending time with living Elders while they can. As a result, most language programs—and those who work with them, and their languages—have a backlog of un-transcribed recordings.
There are several efforts underway to develop ASR models that work well enough with Indigenous languages to reduce the transcription bottleneck and make these recordings accessible to community members. At CEDaR, we use ReadAlongStudio, created by research teams at the National Research Council Indigenous Language Technology Project, to align text and sound (and create picture books) for Gitxsan, Kwak̕wala and other languages. We’re currently testing a toolkit developed by Rolando Coto-Solano to use a small amount of transcribed audio in Kwak̕wala-Bak̕wa̱mk̓ala to fine-tune a Wav2Vec2 ASR model.